
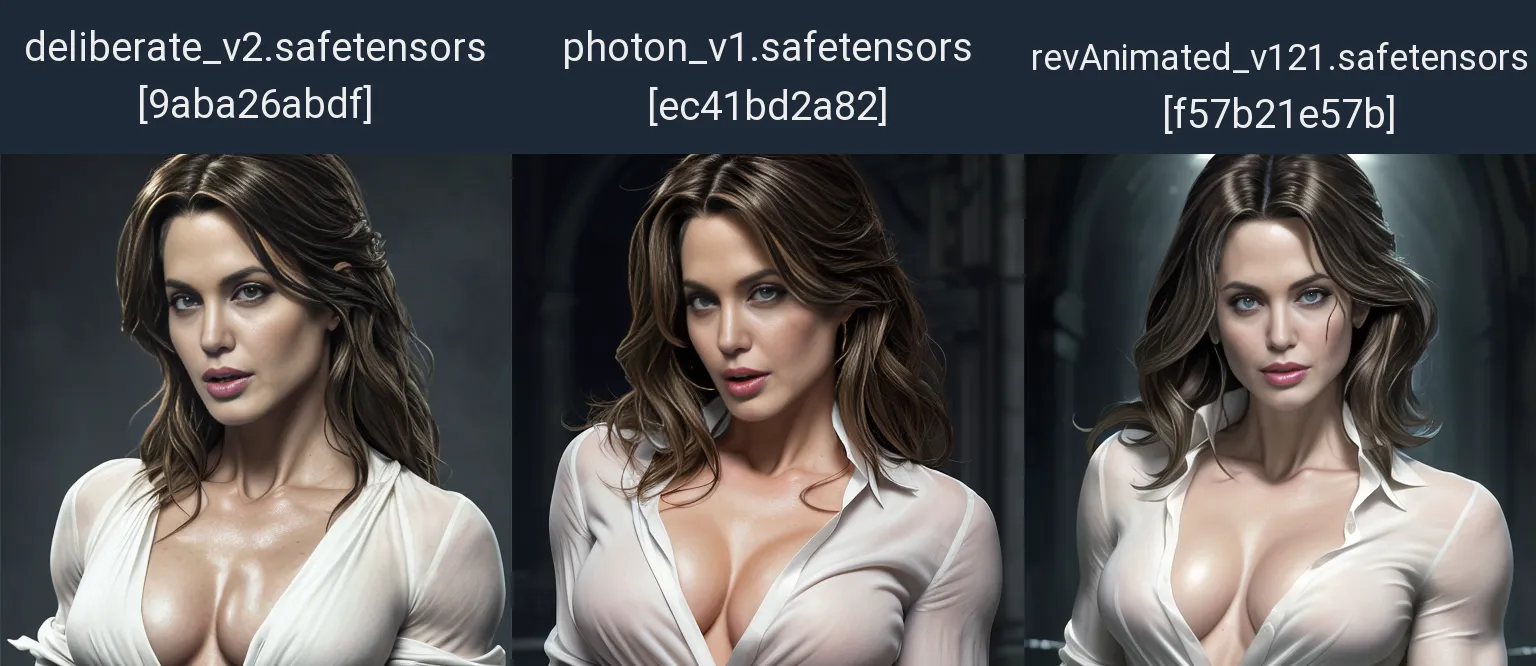
ИСХОДНИКИ
-

- Исходник 1

-

- Исходник 2
-

- Референс 1 — Rowan Atkinson

-
- Референс 1 — Angelina Jolie

-

- Референс 2 — Angelina Jolie

-

- Референс 3 — Angelina Jolie

XL и ip-adapter / InstantID
-

- Исходник сгенерированный на SD1.5
-
- Референс 1 — Angelina Jolie
Сравнение ip-adapter_face_id и ip-adapter_face_id_plus


Instant_ID тест позы головы


XL и Lighting модели, тест на разных семплерах
-

- juggernautXL_v9Rundiffusionphoto2+ip-adapter_face_id+ip-adapter-faceid_sdxl

-
- dreamshaperXL_lightning+ip-adapter_face_id+ip-adapter-faceid_sdxl

-
- juggernautXL_v9Rundiffusionphoto2+ ip-adapter_face_id_plus + ip-adapter-faceid-plusv2_sdxl

-
- dreamshaperXL_lightning

Тест параметра Denoising strength на разных препроцессорах Lighting и обычной XL модели













XL и ip-adapter / PuLID
-
- Исходник сгенерированный на SD1.5
-
- Референс 1 — Angelina Jolie
Тест CFG на примере "обычной" XL модели
-

- Исходник на CFG=7

-
- CFG=1

-
- CFG=2

-
- CFG=7

Тест Шагов на Lighting модели




SD1.5 и ip-adapter в режиме txt2img
-
- Исходник сгенерированный на SD1.5
-
- Референс 1 — Angelina Jolie
-
- ip-adapter_clip_sd15 +ip-adapter-full-face_sd15

-
- ip-adapter_clip_sd15 + ip-adapter-plus-face_sd15

-
- ip-adapter_clip_sd15 + ip-adapter-plus_sd15

-
- ip-adapter_clip_sd15 + ip-adapter_sd15

-
- ip-adapter_clip_sd15 + ip-adapter_sd15_light

-
- + FaceSwapLab и Reactor

-
- + FaceSwapLab и Reactor

-
- + FaceSwapLab и Reactor

-
- + FaceSwapLab и Reactor

-
- + FaceSwapLab и Reactor

-
- ip-adapter_face_id + ip-adapter-faceid_sd15

-
- ip-adapter_face_id_plus + ip-adapter-faceid-plus_sd15

-
- ip-adapter_face_id_plus + ip-adapter-faceid-plusv2_sd15

-
- + FaceSwapLab и Reactor

-
- + FaceSwapLab и Reactor

-
- + FaceSwapLab и Reactor

-
- ip-adapter_face_id + ip-adapter-faceid_sd15 + ip-adapter-faceid_sd15_lora

-
- ip-adapter_face_id_plus + ip-adapter-faceid_plus_sd15 + ip-adapter-faceid_plus_sd15_lora

-
- ip-adapter_face_id_plus + ip-adapter-faceid_plusv2_sd15 + ip-adapter-faceid_plusv2_sd15_lora

-
- ip-adapter_face_id + ip-adapter-faceid_sd15 + ip-adapter-faceid_sd15_lora +FaceSwapLab + ReActor

-
- ip-adapter_face_id_plus + ip-adapter-faceid_plus_sd15 + ip-adapter-faceid_plus_sd15_lora +FaceSwapLab + ReActor

-
- ip-adapter_face_id_plus + ip-adapter-faceid_plusv2_sd15 + ip-adapter-faceid_plusv2_sd15_lora +FaceSwapLab + ReActor
-

- FaceSwapLab v1.2.7 — референс 1
-
- ReActor — референс 1

-
- FaceSwapLab + ReActor — референс 1+2

-
- Если вставить имя и оно известно модели




SD1.5 и ip-adapter в режиме inpaint маски
-
- Исходник сгенерированный на SD1.5
-
- Референс 1 — Angelina Jolie
-

- Маска

-
- Если бы мы и модель знали Angelina Jolie

-
- ip-adapter-plus-face_sd15
-
- ip-adapter_face_id_plus + ip-adapter-faceid-plus_sd15 + Lora

-
- ip-adapter_face_id_plus + ip-adapter-faceid-plusv2_sd15 + Lora

-
- FaceSwapLab

-
- ReActor
-
- ip-adapter-plus-face_sd15 + ReActor

-
- ip-adapter-plus-face_sd15 + ReActor + FaceSwapLab

-
- ip-adapter_face_id_plus + ip-adapter-faceid-plus_sd15 + Lora + FaceSwapLab + ReActor

-
- ip-adapter_face_id_plus + ip-adapter-faceid-plusv2_sd15 Lora + FaceSwapLab + ReActor



-

- Original+negative

-
- GFPGAN

-
- CodeFormer

-

- Референс 1 — Rowan Atkinson
-
- Ну, кто бы теперь вдул? Использовал чёткую маску в inpaint

-

- img2img и вкладка img2img — без маски, включены все 3 заменялки

-
- inpaint — Теперь влёт можно менять причёски

-
- img2img и вкладка img2img — без маски, включен только ReActor

-
- Inpaint — ну хоть подушки безопасности не забыл


Увеличение изображения после замены лица (заключительный этап)
-
- Заготовка

-

- Первое увеличение
-
- Второе увеличение
-

- При увеличении разница очевидна
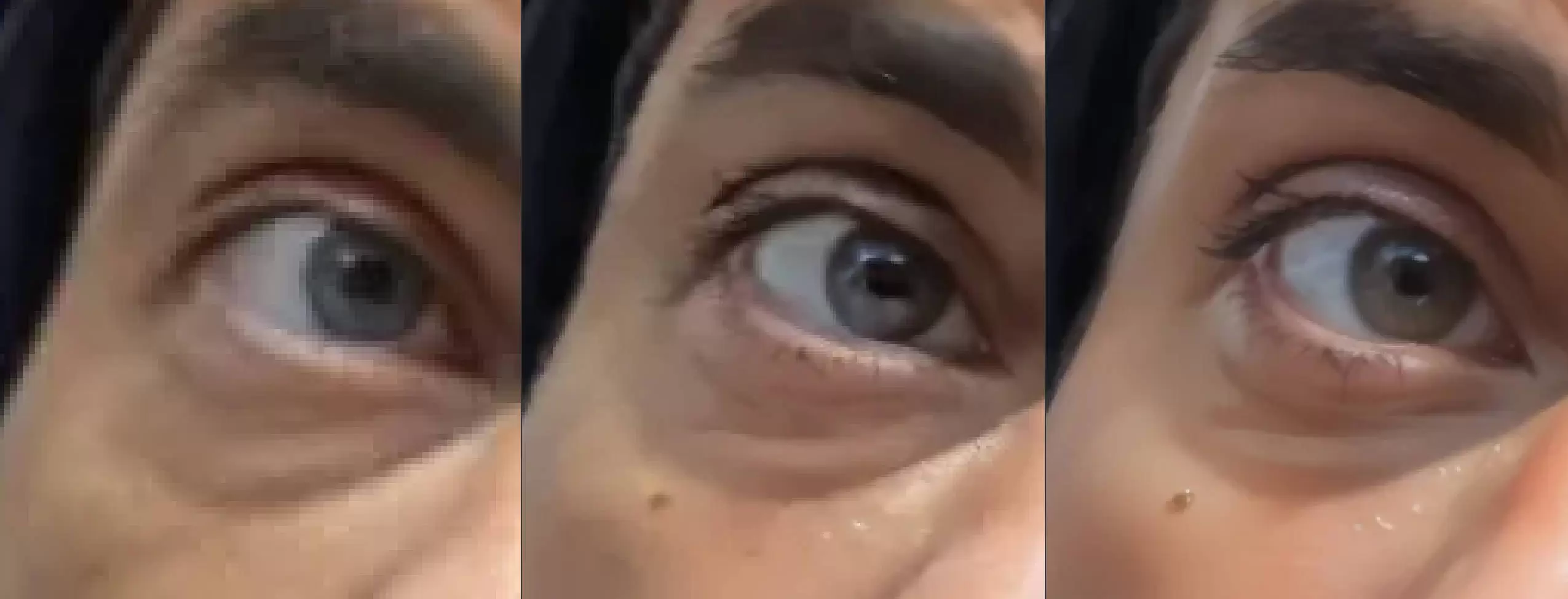
-

- Вот ещё один пример, для закрепления

Замена части лица, одежды
-

- Маска в Inpaint

-

- Референс для IP-Adapter

-

- Маска в Inpaint

-
- Референс для IP-Adapter









Замена головы, лица и тела в разных стилях
-
- Референс лица

-
- Референс 1 — Rowan Atkinson
-

- Маска грубо

-

- Точная маска









-
- Референс 1 — Rowan Atkinson
-
- Точная маска


-

- Реалистик лицо на реалистик тело модель Анимешная

-
- Реалистик лицо на лицо в стиле аниме — модель Реалистичная

-
- Реалистик лицо на лицо в стиле аниме — модель Реалистичная

-
- Реалистик лицо на реалистичное лицо — модель Реалистичная

-
- Референсное тело

-
- Референс лица — выделяем только лицо
-
- Рисуем вне маски

-
- А вот результат если выделить Лицо + Сисячки и трусячки
ТЕСТ ШАГА НАЧАЛА ВКЛЮЧЕНИЯ CONTROLNET
-

- Тест изменения стартового шага

ТЕСТ ШАГА ВЫКЛЮЧЕНИЯ CONTROLNET
-
- Тест конечного шага
ТЕСТ CONTROL WEIGHT
-

- Тест силы стиля
ТЕСТ DENOISING STRENGTH
-

- Тест возможностей внесения изменения
ТЕСТ CFG SCALE
-

- Тест желания следовать указаниям



Замена человеческого лица на нечеловеческое
-
- Исходник 1
-

- Маска исходника

-

- Референс дракона в тумане

-
- Результат
-
- XL модель — MOHAWK_v18VAEBaked Без описания
-
- XL модель — MOHAWK_v18VAEBaked с описанием под лёву

-
- Маска

-

- Референс

-
- Результат
-
- XL модель — MOHAWK_v18VAEBaked без описания
-
- Маска

-
- Референс
-
- Результат

-
- XL модель — MOHAWK_v18VAEBaked с описанием под лёву

-
- Маска исходника
-
- Референс
-
- ip-adapter_clip_sdxl_plus_vith + ip-adapter_sdxl_vit-h

-
- ip-adapter_clip_sdxl_plus_vith + ip-adapter-plus_sdxl_vit-h

-
- ip-adapter_clip_sdxl +ip-adapter_sdxl

-
- Маска

-

- Референс

-
- Результат на Deliberate2

-
- На XL модели — MOHAWK_v18VAEBaked без описания
-
- На XL модели — MOHAWK_v18VAEBaked с описанием под лёву

-
- Маска
-

- Референс

-
- Результат
-
- XL модель — MOHAWK_v18VAEBaked без описания
-
- XL модель — MOHAWK_v18VAEBaked с описанием под лёву

-
- Маска
-

- Референс

-
- Результат
-
- XL модель — MOHAWK_v18VAEBaked без описания
-
- XL модель — MOHAWK_v18VAEBaked с описанием под лёву

-
- Маска
-
- Референс

-
- Результат
txt2img - тест на разных моделях









txt2img ip-adapter-plus-face_sd15 - пример неудачного описания
-
- Референс лица

-
- Начальный Prompt + OpenPose
-
- Начальный Prompt + ip-adapter-plus-face_sd15 + OpenPose

-
- Референс лица
-
- Если в подсказке girl поменять на men — без Cantrolnet

-
- Результат с IP-Adapter (модель ip-adapter-plus_sd15)

img2img тест семплеров и параметров силы (IP-Adapter)
Исходники и результат
-
- Референс лица — выделяем только лицо
-

- Референс лица 258-258 px


ТЕСТ СЕМПЛЕРОВ
-

- Модель photon референс 1638×1638 px

-
- Модель photon референс 1638×1638 px

ТЕСТ DENOISING STRENGTH
-

- Тест Denoising strength
ТЕСТ CFG SCALE
-

- Тест CFG Scale
ТЕСТ CONTROL WEIGHT CONTROLNET
-

- Тест силы ControlNEt
-
- ip-adapter-plus-face_sd15 CW0.5

-
- ip-adapter-plus-face_sd15 CW1

-
- ReActor

-
- FaceSwapLab

-
- ip-adapter-plus-face_sd15 CW0.5 + ReActor

-
- ip-adapter-plus-face_sd15 CW1 + ReActor

-
- ip-adapter-plus-face_sd15 CW0.5 + FaceSwapLab

-
- ip-adapter-plus-face_sd15 CW1 + FaceSwapLab

-
- ip-adapter-plus-face_sd15 CW0.5 + ReActor + FaceSwapLab

-
- ip-adapter-plus-face_sd15 CW1 + ReActor + FaceSwapLab

