почему выбор - stable deffusion?
На текущий момент (*шёл 2024год) Photoshop сервисы типа Midjourney - это конечно хорошо, но если не вдаваться в дебри с измерениями детородных органов, то у них всех есть два существенного недостатка:
- функционал генерации жёстко ограничивается политикой компании - нельзя сгенерировать знаменитую тяночку в чём мать родила и "нагнуть" её в определённой позе. В принципе из-за этого они пригодны только для "правильных" генераций, Midjourney пригоден для референсов, а Photoshop для финальной обработки. И всё бы ничего, но эти ограничения накладывают отпечаток на вполне себе безобидные задачи.
- функционал органичен используемой моделью в которую "вшиты" стили, таким образом нельзя дообучить генерировать ваши любимые "блюда" или применить стиль определенного художника - ибо компания "уважает" чужую интеллектуальную собственность одновременно защищая свою, которая приносит им обоим баблишко.
Midjourney - крут, спору нет, но для новичков которые хотят что-то написать и получить "Вау" эффект. При этом SD не имеет ограничений и может всё тоже самое что и Midjourney, но только при условии грамотного составления описания/негатива и применения парочки расширений с правильно подобранными моделями и настройками - только в таком случае выбор становится очевиден. Если у кого-то остались сомнения - можете зайти на civitai и посмотреть примеры работ мастеров. А то, как сделать так и даже лучше - это и есть миссия сайта на котором вы читаете этот материал. Поэтому здесь и далее мы будем рассматривать в основном нейросеть Stable deffusion в оболочке AUTOMATIC1111 и уже потом в отдельном разделе потихонечку постигать кон-фу в ComfyUI.
Сама нейросеть Stable deffusion (SD) может быть обёрнута в различные интерфейсы, может работать как непосредственно у Вас на компьютере, так и у чужого дяденьки типа Google. Так же существует масса онлайн сервисов которые прикрутили к своим сайтам возможность генерации SD в той или иной мере - но все они имеют ограничения по сравнению с установленной локальной версией лично у вас на компьютере.
Однако стоит отметить, что необходимо иметь минимум 8 ГБ видеопамяти на борту карточки Nvidia и более на Radeon'ах для более или менее комфортной работы. Можно конечно извратиться и на 4 или 6 ГБ при условии карты Nvidia, или вообще использовать CPU вместо GPU - но это будет явно доставлять меньше удовольствия, ибо генерация увеличиться в разы, возможны вылеты и прочие ошибки в работе ПО.
Как уже говорилось SD может быть обёрнут в различные оболочки:
- AUTOMATIC1111 - самая неудобная, но при этом позволяющая воплотить вашу фантазию на 100% благодаря таким расширениям как Controlnet и режимам inpaint. Т.е. вы получаете результат соответствующий вашему запросу с последующей коррекцией в едином интерфейсе, понятное дело что сценариев работы при таком подходе довольно много, от этого и вкладочек с настроечками овердохера, так что при первом взгляде можно словить ступор. Однако через пару недель глаза бояться а руки делают и становится уже не так страшно. А вместе мы сможем разобраться во всех тонкостях и достичь нужного результата.
- Forge - перенастроенная сборка AUTOMATIC1111, имеет аналогичный интерфейс, но большую производительность на RTX видеокартах, от 15 до 30%. Есть ещё небольшие отличия в Controlnet - например можно рисовать маску для применения моделей к разным областям изображения, а так же содержит новый препроцессор глубины depth_marigold. Так же есть парочку расширений отсутствующих в AUTOMATIC1111, такие как SelfAttentionGuidance Integrated - делает генерации более правильными с точки зрения логики к элементам композиции. Или расширение StyleAlign Integrated - при генерации Batch size (групповой генерации) - выдаёт пачку немного отличающихся изображений. А так же другие полезные и не особо расширения.
- Fooocus - упрощённая оболочка по сравнению с AUTOMATIC1111, работающая быстрее и интуитивно понятнее. Предназначена для быстрого решения большинства задач по генерации. Больше скорость, меньше настроек, но и меньше контроля соответственно.
- ComfyUI - это нодовая система, ещё более сложная из всех разновидностей Stable Diffusion. Однако самая быстрая и гибкая в плане возможностей. Больше предназначена для решения однотипных задач, нежели реализации творчества ввиду необходимости настройки под конкретные задачи, отсутствием компонентов (нод) из коробки, ошибок в консоли и прочих прелестей. Данная оболочка будет незаменимым помощником для реализации сервисов с решением конкретных задач. Однако благодаря возможности использования сторонних рабочих процессов путём банального перетаскивания картинки в рабочую область - позволяет быстро переключаться между задачами и щёлкать их как орешки.
Итого, если у Вас 8ГБ и менее видеопамяти, а так же если Вы нацелены на профессиональный подход для решения конкретных задач - то ваш выбор это ComfyUI. Если у Вас около 12 ГБ, а Вы больше нацелены на реализацию своих творческих разнообразных задумок - то выбирайте Forge или AUTOMATIC1111. Если у Вас простенькие задумки и нет времени вникать во все тонкости и нюансы - то выбирайте Fooocus. Тем не менее, освоив одну из оболочек Вам будет заметно легче осваивать другие. Несмотря на разницу в интерфейсах, основные понятия и определения одинаковые, поэтому рекомендуется начать с любой оболочки и не боятся экспериментировать.
параметры главного окна Stable Deffusion в оболочке AUTOMATIC1111
AUTOMATIC1111 - это оболочка нейросети под названием Stable Deffusion. Далее будем говорить SD или Stable Deffusion, но иметь ввиду AUTOMATIC1111 или Forge.
В целом, определения будут не лишними и для других оболочек и нейросетей, т.к. общий принцип действия у них одинаковый, а отличаются интерфейсом, доступными настройками, расширениями, а так же доступными моделями.
Токены - по простому это слова или их сочетания, в том числе с числами. Точки, запятые и другие символы, влияющие на суть композиции так же влияют на итоговую генерацию ни чуть не меньше чем сами токены. Однако на самом деле Токены представляют из себя набор вероятных параметров - векторы весов распределённых в многомерном пространстве данных, которые передаются из модели для преобразования исходного шума в изображение соответствующее описанию. В зависимости от наличия токенов, их расположения, сочетания и контекста, все токены преобразуются в соответствующие элементы изображения наиболее подходящие описанию, при условии что токены расположены в позитивной подсказке (далее просто подсказка) и наоборот - исключаются элементы если токены расположены в негативной подсказке (далее просто негатив). Совокупность подсказки, негатива и настроек генерации называется Prompt (далее просто Промпт) Процесс исключения и добавления элементов происходит на каждом шаге генерации (Steps), количество которых зависит от основной модели генерации (checkpoint).
Ещё раз, Токены следует рассматривать не как слова, а как набор наиболее вероятных параметров, при этом они могут:
1) быть составной частью другого набора параметров. Например токен "лысый" = наиболее вероятному токену "без волос" который в свою очередь является составной частью "гладко выбритая верхняя часть головы" и т.д.. Таким образом, Токен передаёт целую группу наиболее вероятных параметров, у каждого из которых есть свой вес - приоритет.
2) игнорироваться, если модель не обучена на соответствующих примерах. Например токен "без" если он не является составной частью другого токена, будет игнорироваться и приводить к противоположному результату (см. пример).
В итоге, если прописать HD, 4K или High quality данные токены могут привести к повышению контраста или накидыванию деталей, что вводит людей в заблуждение о повышении качества, хотя на самом деле из модели выбираются лишь некоторые дополнительные, наиболее вероятные, параметры и они не факт что соответствуют определению этих самых токенов.
Понимаю, что всё запутанно, но это очень важное основополагающее понятие, перечитайте несколько раз и потом ещё парочку, что бы закрепить этот аспект.


Таким образом, многое будет зависеть от того, знает ли модель не только сам токен и его сочетания, но и близкие по смыслу значения - синонимы. Синоним - это словечко для упрощения понимания, на самом деле это наиболее вероятные параметры полученные путём разделения многомерного пространства векторов весов с помощью функции полученной при обучении на конкретном токене или их сочетаниях.
Результат будет строиться не на выдаче конкретного параметра, а на предсказывании наиболее вероятных значений параметров (векторы весов). То есть, если прописать в подсказке 2 токена "Не девушка", "без пальто", "без шапки" или "без сигареты" приводит к тому, что первый токен игнорируется, т.к. модель не обучена всем возможным вариантам с частицей "не" и нельзя заменить его неким синонимом, и как следствие наиболее вероятные параметры приводят к прямо противоположному от ожидаемого результату. Однако сочетание "без волос" делает именно то что должно, потому что модель обучена данному сочетанию или его аналогу "лысый", т.е. модель рисует именно мужчину без волос. как наиболее вероятный вариант. Аналогично, если прописать "Красивая девушка" как и "Не красивая девушка" - даже если модель не обучена этому сочетанию, всё равно будут передаваться наиболее вероятные параметры: девушка, тип причёски, наличие макияжа, состояние кожи и т.д..
Для исключения объектов следует пользоваться негативной подсказкой. А всё что в позитивной подсказке - должно рисоваться наиболее вероятным способом. А вероятность правильности отображения токена зависит не только от того передавался ли соответствующий параметр, но и от Seed который даёт безусловное изображение, а так же от такого параметра как CFG влияющего на количество передаваемых параметров и их выборку из основной модели.
Для примеров будем использовать ниже представленный Промпт, его можно целиком скопировать, вставить в подсказку и нажать синюю галочку под кнопкой Генерации, после чего все настройки автоматически пропишутся. Так же следует учесть, что если не все, то многие сгенерированные картинки на этом сайте содержат информацию о генерации и ещё одним способом вставки Промпта является возможность перекинуть картинку путём перетаскивания в область описания (хотя в некоторых браузерах нужно предварительно сохранить картинку в полном размере):
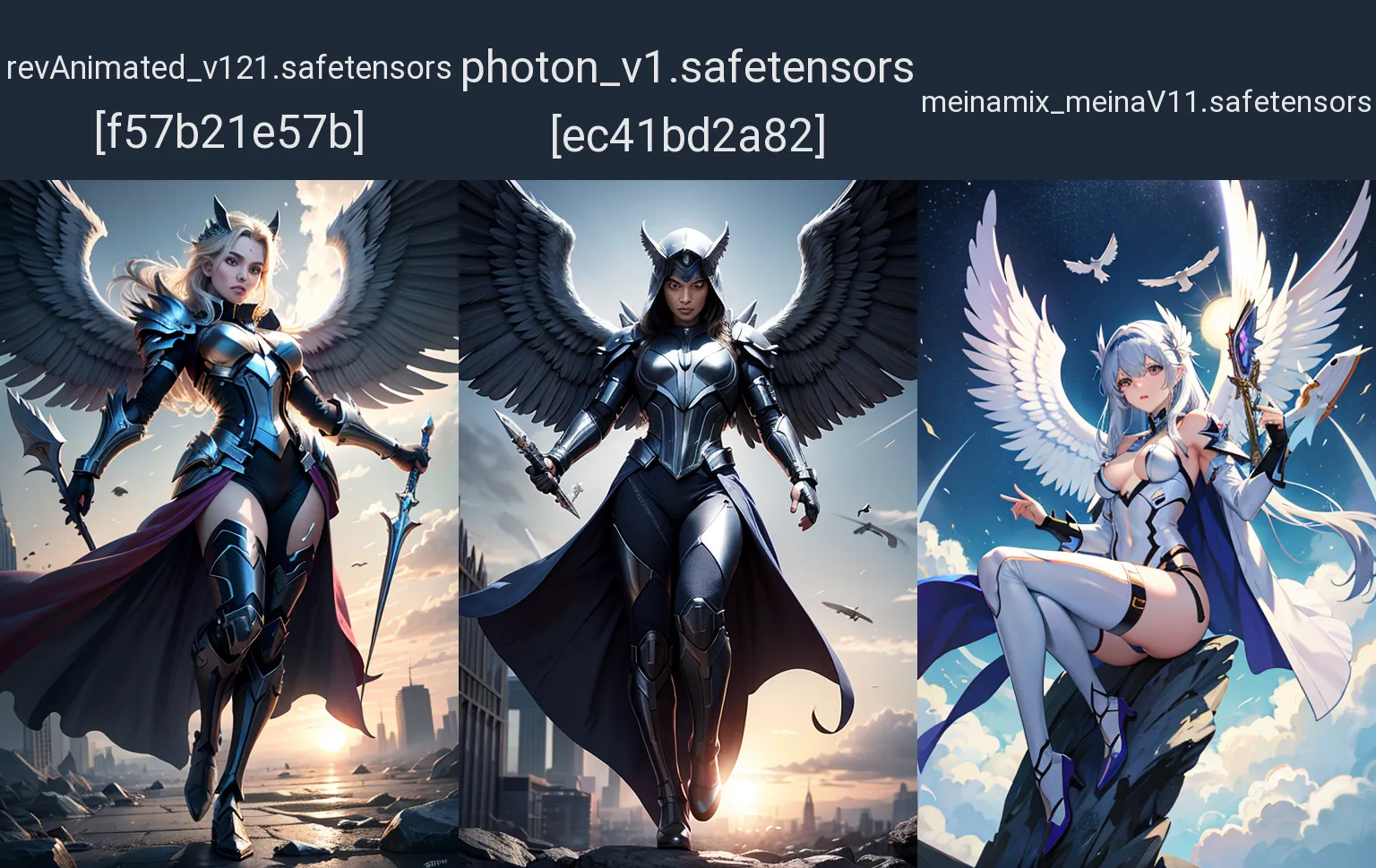
archangel
Negative prompt: (worst quality:2), (low quality:2), (normal quality:2), dot, mole, lowres, cropped, jpeg artifacts, ugly, duplicate, morbid, mutilated, out of frame, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, mutation, deformed, bad anatomy, bad proportions, extra limbs, cloned face, disfigured, gross proportions, malformed limbs, missing arms, missing legs, extra arms, extra legs, fused fingers, too many fingers, long neck
Steps: 20, Sampler: DPM++ 2M Karras, CFG scale: 7, Seed: 1, Size: 512x768, Model hash: f57b21e57b, Model: revAnimated_v121, VAE hash: 15e96204c9, VAE: vae-ft-mse-840000-ema-pruned.ckpt, Version: v1.6.0
Модель для генерации - это набор данных полученный путём "тренировки" на исходных изображениях. Образно представляет из себя многомерное облако с векторами весов, которые распределяются относительно загруженного датасета с исходными изображениями и описаниям к ним. В зависимости от качества тренировки модели - будет зависеть качество генерации. Модели можно смешивать между собой и дотренировывать своими наборами картинок и описаниями к ним, таким образом обучать модель понимать новые стили, токены, а так же изменять текущие представления.

Модель можно образно представить как кучу данных с рецептами наших любимых тяночек, соответственно если никто модель не учил как выглядит наша физиономия - то увы, она его навряд ли нарисует по описанию. Однако эта задача легко решается с использованием соответствующих расширений, или обучением специальных минимоделей встраиваемых в процессе генерации в изображение.
От модели, настроек и прямых рук будет зависеть большая часть результата. Модели размещаются по пути: StableDiffusion\models\Stable-diffusion\
Модели могут размещаться кучей непосредственно в корне папки или их можно рассортировать по подпапками, например можно создать отдельную папку для реалистичных моделей, для аниме или для SDXL. В примере выше создана папка REALISTIC-- и в неё помещена одна из моделей.
Отличие моделей:
- По версиям базовой модели, на которой тренируются целые линейки, самые популярные и лучшие: XL, SD1.5. Отличие в датасете, разрешении и количестве шагов. Интересны не сами базовые модели, а дотренированные модели и их миксы, удобнее всего их качать с сайта civitai.com
- Кроме того, модели могут делиться на Lightening, Turbo и LCM которые помимо используемой лицензии и методов обучения, будут отличаться, более быстрой генерацией, за счёт уменьшения количества шагов, но в ущерб относительной потери качества. Однако, эти модели просто незаменимы при необходимости быстрой генерации, а качество вполне достаточное для некоторых случаев. Ещё есть модели Cascade, а в будущем появятся многие другие. Описание каждого вида модели смысла нет, нужно смотреть примеры и описания к каждой конкретной модели, например на сайте Civitai.com
- Формат ckpt и safetensors - последний безопаснее.
- fp16/fp32/bf16... - разрядность влияющая на точность и скорость. fp16 - берём для повседневного использования, fp32 - для тренировки Lora. Тенденция идёт к уменьшению разрядности, но благодаря более качественному набору данных и алгоритмам их обработки, можно увеличить скорость путём незначительного "изменения" качества.
- Pruned - немного обрезанная модель в плане точности, но для простого смертного это больше плюс чем минус, т.к. весит меньше и работает шустрее.
- inpaint - модель в основном используемая для генерации в определённой области (например на вкладочке img2img-inpaint) способная нарисовать в пустом месте что-то по запросу. Обычная модель пытается что-то слепить из пикселей в выделенной области.
Для некоторых моделей требуется файлик yaml - конфигурационный файл для корректной работы Автоматика с определённой моделью и расширениями. Называется так же как основная модель и лежит рядышком.

AUTOMATIC1111 - предлагает развёрнутый вариант графического взаимодействия человека с Stable Deffusion посредством WEB интерфейса, поэтому будем рассматривать основные понятия на этом интерфейсе. Позже нам пригодятся эти знания и для других интерфейсов.
Итак, в настройках Stable Deffusion (имеем ввиду что говорим про автоматик1111), на вкладке User interface можно добавлять любую настройку для быстрого доступа с главного экрана в верхней части. Рекомендуется вывести часто используемые элементы, для этого достаточно ввести часть названия и выбрать из найденного.
Отображение данных параметров можно включать/отключать в настройках на вкладке User interface в пункте [info] Quicksettings list (бла бла бла).

VAE - если кратко, то эта штука отвечает за постобработку выходных данных преобразуя их в изображение понятное человекообразному. А ещё проще говоря - влияет на цветокоррекцию, чёткость и даже мелкие детали типа глаз. VAE может быть встроена в модель или выставляться отдельно в настройках. VAE грузится в VRAM (видеопамять). Какую VAE использовать и стоит ли вообще использовать, смотрите рекомендации к основной модели.
VAE находятся по пути StableDeffusion\models\VAE
*Если на последнем шаге генерации получите чёрный/серый квадрат Малевича ИЛИ пережжённое ИЛИ как бы недогенерированное изображение - копайте в сторону VAE.
Если в названии модели указано baked - значит в ней уже зашита какая-то нестандартная своя VAE. no vae - означает что вшита стандартная VAE. Хотя больше следует полагаться на описание к модели, нежели на её название, ибо хрен его знает что было в уме и что курил разраб когда пилил очередную модель.


Любое изображение можно разбить на слои, каждый из которых будет отвечать за наиболее вероятную часть описания. Clip skip - отвечает за пропуск указанного количества слоёв начиная с менее важных - "с конца" давая тем самым творческую свободу основной модели. Эта настройка очень сильно зависит от того как тренировалась модель, поэтому смотрим рекомендации разработчика. Очень часто модели и даже LORA дают более интересный результат на clip skip = 2. Если копнуть глубже, то Clip - это не совсем слои, а плоскости в форме функции делящие многомерное пространство векторов с весами на части, чем больше таких плоскостей, тем больше отсекают из этого пространства менее вероятные значения соответствующие вашим токенам, что в теории должно повысить точность следования подсказке. Однако, если мы работаем с сжатой, пережатой, миксованной моделью, дотренерованной хрен пойми как, то результат будет не столько точным, сколько ограниченным, что приведёт к ухудшению качества генерации. Отсюда вывод - следуйте рекомендациям разработчика модели, он хотя бы опытным путём уже проверили это утверждение.
параметры генерации
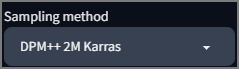
Если человеку показать кляксу чернилами на белом листе то он начнёт воображать и придумывать на что она похожа, толи бабочка толи взрыв мозга... Вот и Sampling method - это математический метод определения изображения согласно Вашему описанию, только не из кляксы, а из шума пикселей. Все семплеры делятся на сводимые к конечному результату и те которые постоянно подмешивают шум на каждом шаге генерации и от того никогда не приходят к конечному результату.
Ряд семплеров быстрее сводят изображение и лучше выдают изображение на небольшом количестве шагов, другие работают дольше, но при этом дают больше деталей. Третьи семплеры кривожопые специфичные по природе и их можно отключить в Настройках на вкладке Sampler parameters.
В целом, следует придерживаться рекомендаций разработчика основной модели. А уже после того как освоите 2-3 семплера пробовать другие. Подробнее про семплеры будет отдельный материал.

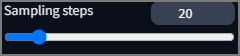
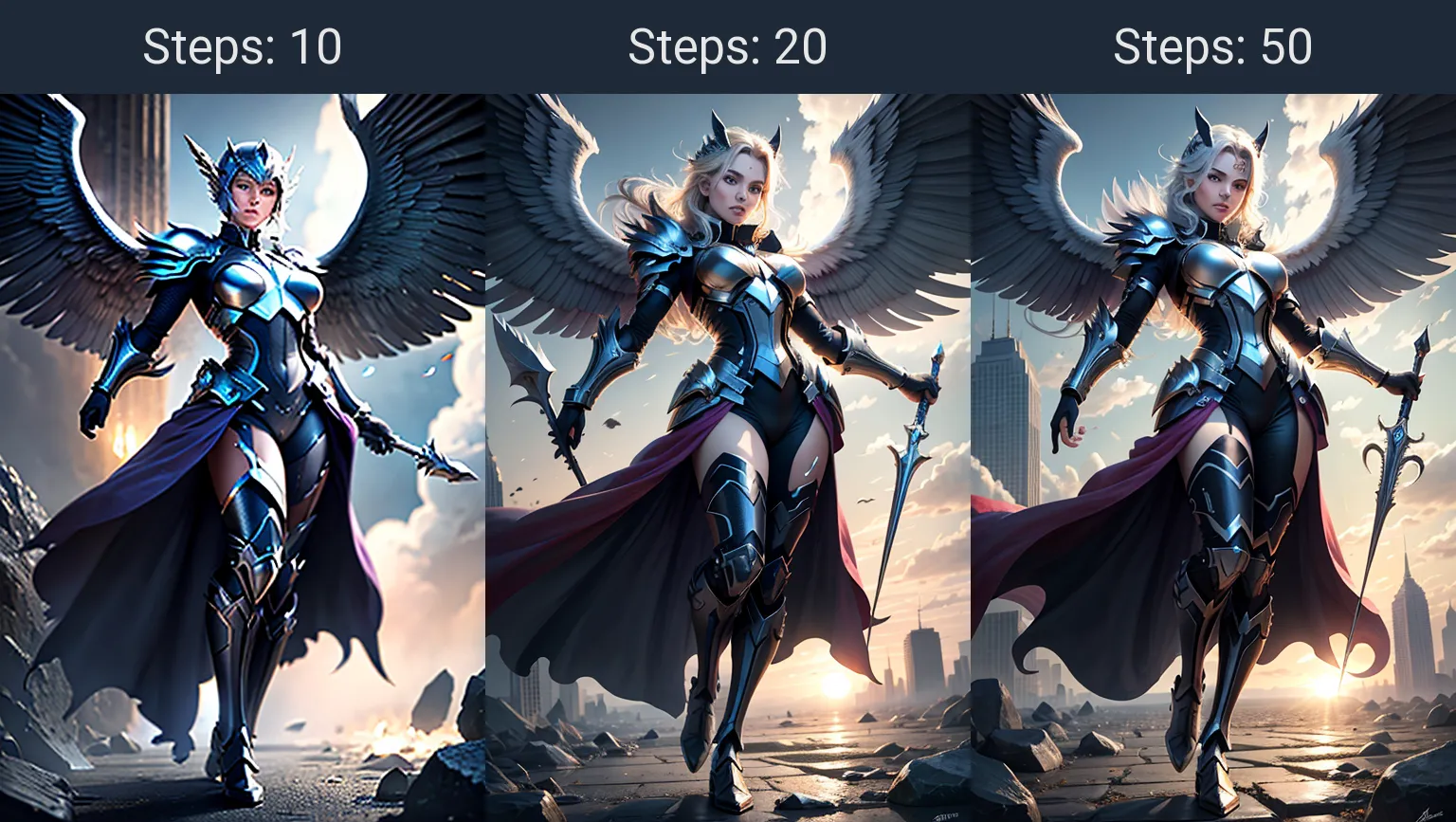
Шаги определяют количество итераций за которые модель и методы должны сформировать изображение согласно подсказке. Опять-таки зависит от рекомендаций разработчика используемой модели. По умолчанию = 20 для обычных моделей SD1.5 и SDXL. Но меньше, или больше не значит хуже. На некоторых подсказках и сэмплерах можно понизить шаги для получения нужного эффекта, или наоборот увеличить что бы повысить качество деталей. Для Turbo и lighting моделей, количество шагов уменьшено ввиду большего количества передаваемых параметров за раз, поэтому внимательно читайте рекомендации разработчика.
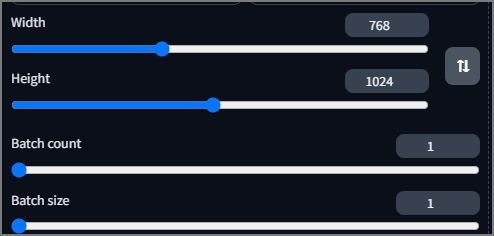
Главное что следует помнить при изменении размеров - это то, что они должны быть кратными 8. Так же следует придерживаться рекомендаций разработчика, обычно (но совсем не обязательно) для SD1.5 это 512 х 512, для SDXL 1024 х 1024. Но некоторые модели SD1.5 способны вполне хорошо работать на разрешении вплоть до 1024 особенно при использовании ControlNet. Для ландшафта и портрета важно соответственно соотношение сторон, горизонтальная или вертикальная ориентация.
Batch count отвечает за количество последовательно генерируемых изображений, а Batch size за количество одновременно генерируемых изображений что иногда существенно быстрее (от 20 до 30%) но при этом немного более требовательно к видеопамяти (на 10-20%) и не позволяет генерировать более 8 одновременно.
Следует учесть, что использование Batch, в ряде случаев, приводит к незначительным, но всё же изменениям композиции, что в свою очередь приводит к невозможности 100% повторяемости результата при отдельной генерации.

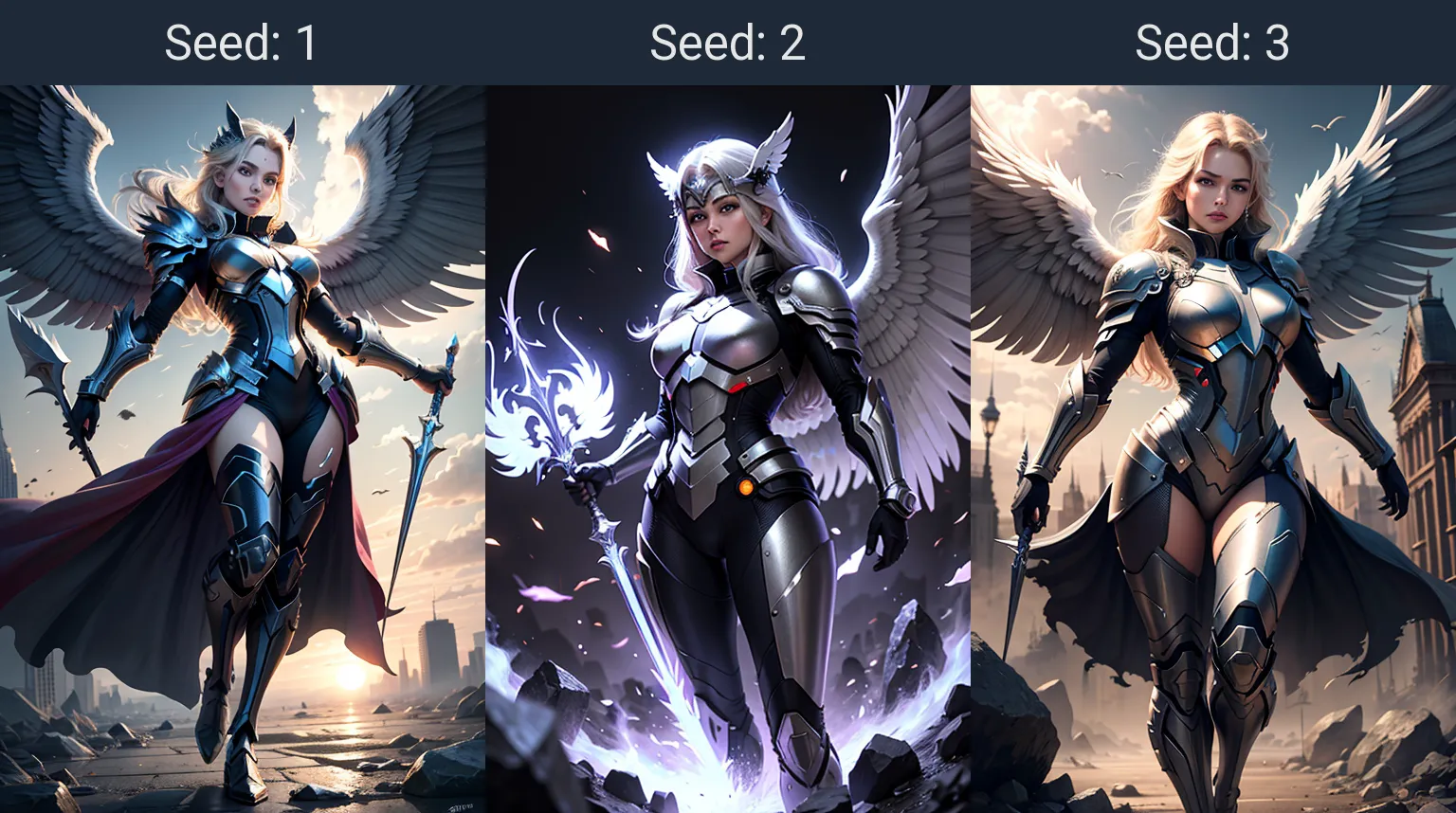
Seed - позволяет зафиксировать начальный шум для повторения результата генерации при одинаковых параметрах. Или наоборот, изменяет начальный шум для изменения изображения на одних и тех же настройках. Таким образом можно без проблем повторить генерацию или получать вагон и маленькую тележку разнообразных вариаций изображений по одной и той же подсказке.
Если капнуть чуть глубже, то Seed влияет на безусловное изображение полученное при генерации с пустой подсказкой и без негатива. Именно с этим изображением смешиваются токены из подсказки и вычитаются токены из негатива, на каждом шаге генерации.

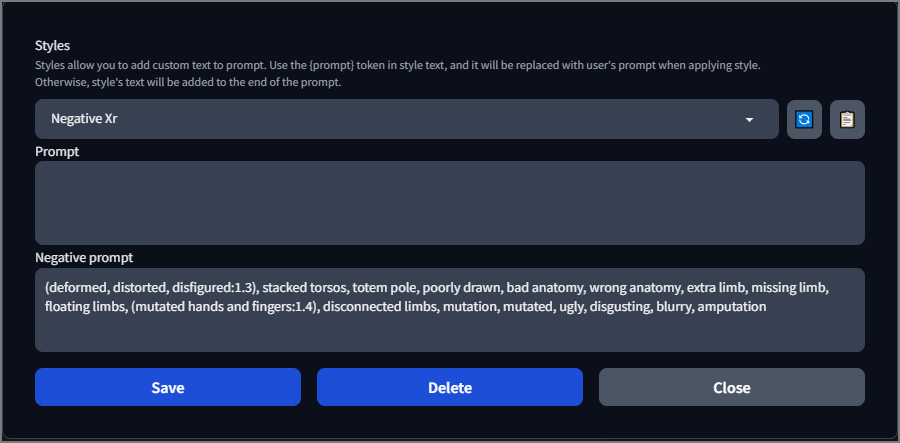
Стили - это те же самые описания и негативы только в виде более удобного списка для быстрого выбора. Причём описание помещённое в главную подсказку можно разместить в любом месте стиля. Кстати, обычно под стилями понимаются именно дополнительные настройки генерируемого изображения, а не полная подсказка к изображению, хотя в них можно можно запихнуть что угодно: негатив, как общий так и на отдельные элементы | описание стилей художников и их самих | настроек вида камеры, перспектива, апертура, эффекты линз, размытия заднего фона и т.д. | применение определённой цветовой палитры | виды с разных сторон...
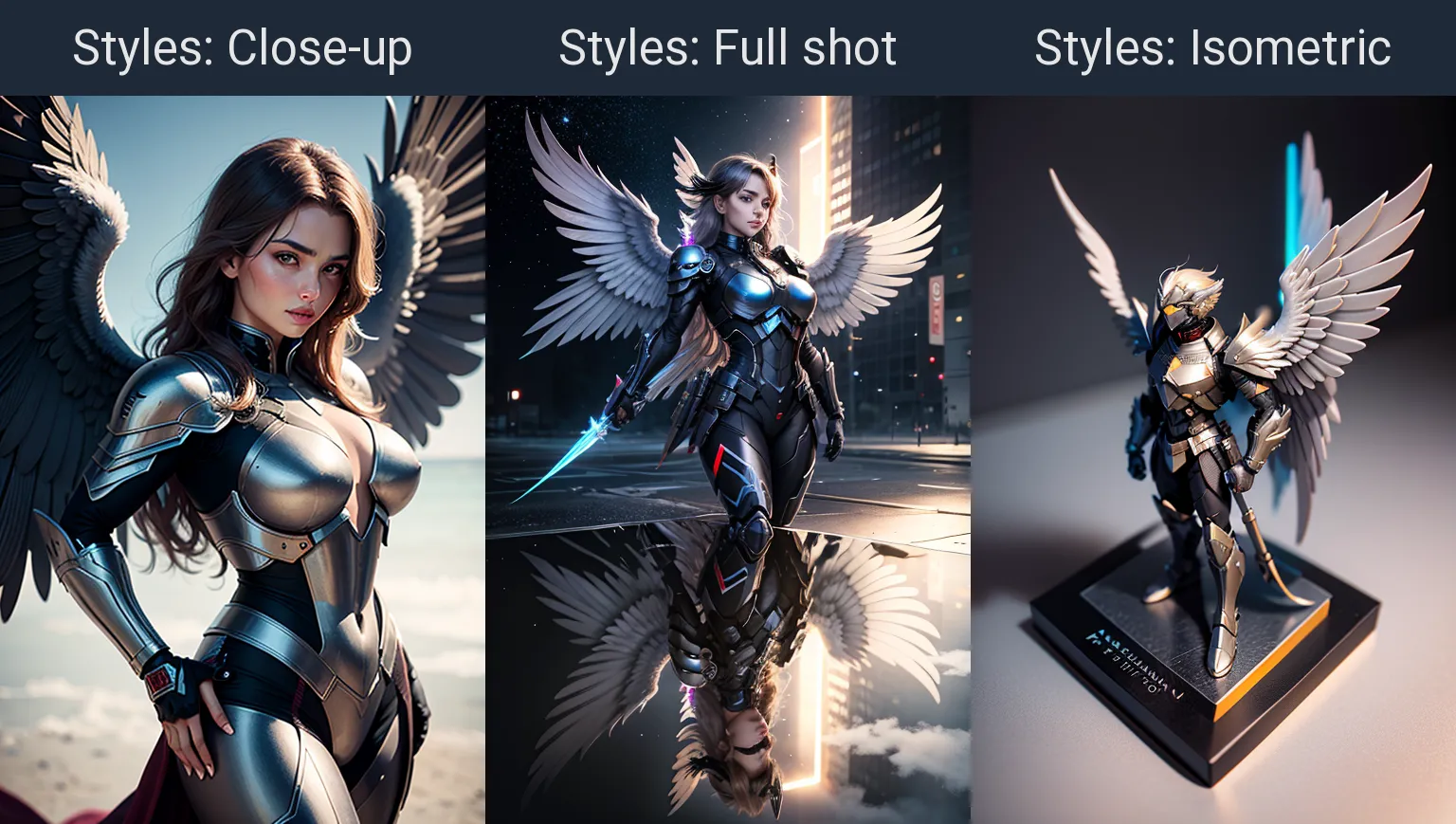
CFG (метод Classifier-Free Guidance Scale) использует сочетание двух изображений:
- безусловное изображение, изображение полученное из шума и фиксируемое значением seed. Это начальное изображение получено без учёта текстовой подсказки и негатива
- условное изображение полученное по выборке параметров токенов из подсказки, И чем больше значение CFG, тем больше параметров по каждому токену получает генерация, соответственно повышается степень доминирования над безусловным изображением, а при чрезмерном значении - "пережарка" изображения, как если бы мы в течении длительного времени обводили ручкой круг от нефиг делать.
Эти изображения смешиваются друг с другом в процессе генерации и уже из него удаляется элементы соответствующие токенам из негативной подсказки, этот процесс повторяется на каждом шаге (Steps).
Получается, что чем ниже CFG Scale, тем нейронка больше следует безусловному изображению, итоговое изображение получает больше вариативности в зависимости от Seed. создавая тем самым иллюзию свободы творчества, а чем больше — наоборот, изображение начинает ограничиваться рамками токенов каждый раз дорисовывая детали к итоговому изображению, но при определённом превышении параметра CFG дорисовывать уже нечего и нейронка начинает страдать фигнёй обводя существующие элементы, повышая тем самым их контрастность, вызывая эффект насыщенности и в конечном счёте "пережённости". При зафиксированном seed разумеется ни о какой вариативности применительно к CFG Scale речи не идёт.
CFG scale - количество параметров передаваемых на каждом шаге для условного изображения которое смешивается с безусловным изображением полученным из шума, который в свою очередь зависит от Seed и основной модели генерации. В Lighting и Turbo моделях количество передаваемых параметров на каждом шаге увеличено ввиду меньшего количества шагов рекомендуемых для моделей. Поэтому внимательно читайте рекомендации к моделям.
Таким образом, на реалистичной модели генерации, чем меньше CFG - тем более реалистичное выходит изображение, но меньше используется подсказка, Чем больше CFG - тем более цветастым становится изображение и картинка изворачивается максимально для реализации написанного в подсказке с крупицей исходного безусловного изображения.



Включаются разворачиванием, выключаются сворачиванием вкладки. Если развёрнуты обе вкладки, то работает в приоритете Hires. fix.
Hires. fix - инструмент для повышения разрешения с регулировкой вносимых изменений при выполнении этого процесса. Для увеличения используются специальные модели называемые Upscaler размещённые в папке StableDif\models\ESRGAN\
Одни Апскейлеры предназначены для увеличения Аниме, другие для фотореалистичных изображений, третьи лучше прорисовывают некие элементы - в общем без 100 грамм не разобраться. Будет отдельный материал на эту тему. В примере выше 1 - без апскейла, 2 - двухкратный, 3 - трёхкратный апскейл на Denoising strength =0,5. DS обычно ставят меньше, но для примера я поставил побольше и получил вместо самолётов на заднем фоне, каких-то птеродактилей после увеличения. Имейте ввиду, что лица при использовании Hires. fix будут стремиться к некоему стандартному, однотипному лицу. Для правки лиц лучьше использовать отдельное расширение - ADetailer.
Refiner - позволяет на определённом проценте генераций переключиться на другую модель. Рисуете например 30% на Аниме модели, а далее переключаетесь на фотореалистичную!!! В примере ниже первое изображение модель meinamix_meinaV11, вторая картинка photon_v1, а третья смесь 30% первая и на 70% вторая модель.
Незабываем, что дополнительно для XL моделей есть спецрефайнер для увеличения детализации, а не смешивания моделей.






Скрипты предоставляют дополнительные возможности для тестирования описаний. Например можно протестировать разные стили или одно и тоже описание на разных моделях и многое другое используя скрипт X/Y/Z plot. То что Вы видите в данном разделе "помощи" с подписями картинок сверху - это как раз X/Y/Z plot. Список доступных скриптов отличается от того, на какой вкладке Вы находитесь - txt2img или img2img.

дополнительные модели

Generation - основная вкладка параметров генерации.
Textual Inversion, Hypernetworks. Lora - модели вмешивающиеся в процесс генерации основной модели и добавляющие, изменяющие или удаляющие элементы.
Textual Inversion может быть простым способом создать изображение на основе текстового описания. Поможет сделать чебурашку из милого ушастого мишкоподобного Микемауса, но не более. Или убрать лишние конечности явно тыкая нейросеть в то, на что следует обратить внимание. Имеет очень малый размер по сравнению с другими моделями. Текстовые инверсии иначе называются Embeddings и размещаются по пути StableDiffusion\embeddings\
LORA (а также LyCORIS - который объединяет Lora/Locon) позволяют "дообучить" модель в процессе генерации, тем самым добавить в неё незнакомые изначально элементы. Вот, вот где можно научить основную модель натягивать любую физиономию на брутальных персонажей в эпических позах! А так же можно сделать жидкую/горящую/грязную/специфичную одежду, слайдер возраста/мускулатуры/мимики или показать как должен выглядеть тот или иной артист/автомобиль/украшение/стиль художника ранее неизвестный основной модели... LyCORIS сложнее в изготовлении и от того их не так много по сравнению с LORA, но даёт относительно лучший результат при применении.
Вся религия SD сводится к контролю, а следовательно, кроме как применения доп.моделей непосредственно при генерации изображения, ещё одним из способов применения данных моделей, для сохранения композиции, является отправка обычного сгенерированного изображения в img2img и уже там применение Lora/LyCORIS.
Сами модели Lora и LyCORIS размещаются по пути StableDiffusion/models/Lora
Hypernetworks - это аналог LORA поможет настроить параметры модели для более точной генерации накладывая дополнительный слой на генерируемое изображение, образно накладывая фильтр как в фотошопе на каждом шаге. НО по сравнению с LORA качество и гибкость явно хуже. Модели размещаются по пути StableDiffusion\models\hypernetworks\
Активируются приблуды путём установки каретки (указателя места печати) в нужное место подсказки или негатива, с последующим клацаньем на соответствующей иконке. Важно: для активации и усиления эффекта некоторых дополнений требуется дополнительно указать триггерное слово (Trigger Words) которые можно узнать на странице разработчика или откуда Вы там качали 😛
В частности, найти, посмотреть что и как делают с примерами можно на сайте civitai
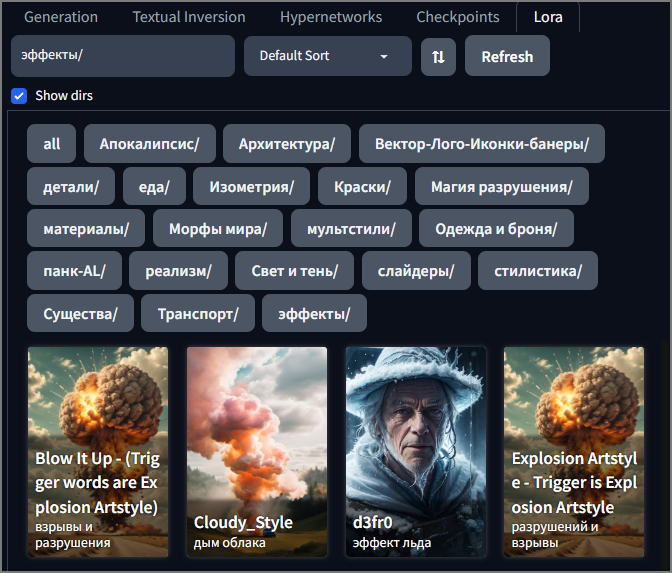
Важной особенностью работы с моделями является возможность их организации по папкам. Например для Lora по пути StableDiffusion\models\Lora\ можно создать паки по тематике и расфасовать по ним все имеющиеся лоры которые были в корне данной папки. Галочка "Show dirs" позволяет показать папки в которых будут показываться только размещённые в них модели. Если рядышком с лорой положить картинку и назвать её так же как и лора (кроме расширения естественно), то мы получим превью. А если навести мышку на превьюшку, то в правом верхнем углу появится значок для добавления/редактирования триггерных слов и занесения примечаний к модели.
Lora для SD 1.5 и SDXL отличаются. В настройках SD на вкладке Extra Networks можно включить/отключить отображение неподходящих Lora под текущую выбранную модель:

скрипты и расширения
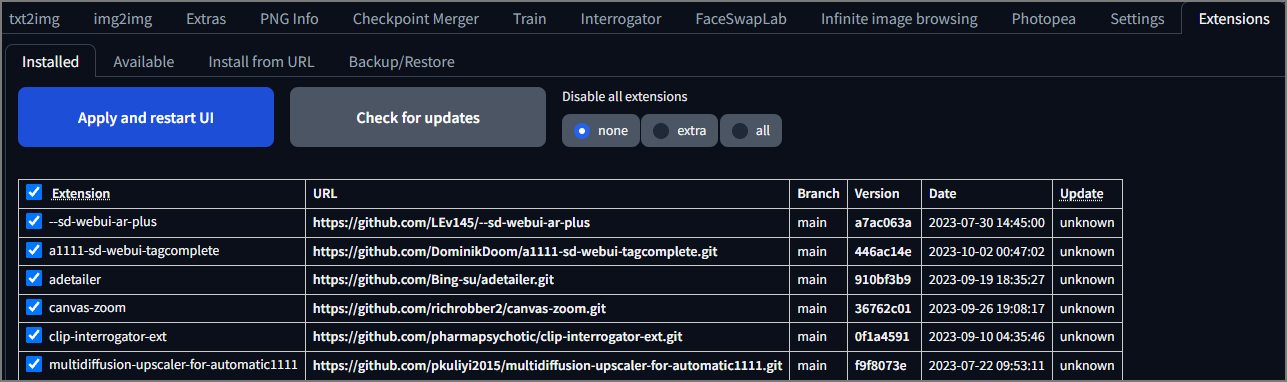
На вкладке Extension можно просмотреть:
- установленные расширения находящиеся в папке StableDiffusion\extensions\
- доступные для установки из списка, находящегося на определённом адресе
- установки по URL с репозитория git
- архивирование и восстановление
Кроме этого, расширения могут устанавливаться путём банального копирования в папку расширений, либо клонированием репозитория через командную строку или .bat файл. Однако некоторые расширения требуют дополнительных манипуляций описанных на странице разработчика,
В зависимости от расширения, оно может размещаться как на уже существующей вкладке, так и отдельной, появиться в списке выбора скриптов только на одной из вкладок и даже во всех местах сразу.
Обновление расширений можно производить с этой же вкладки путём нажатия на кнопку "Check for updates" - проверить обновления. После обновления необходимо нажать "Apply and restart UI" - применить и перезагрузить интерфейс, в идеале закрыть консоль (чёрное окно с буковками) и запустить заново.
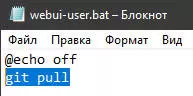
Если расширение не обновляется, а Вы уверены что оно должно обновиться, можно попробовать запустить команду "git pull" непосредственно из папки с расширением, сделать это можно либо создав файл с расширением .bat либо из под командной строки.
На вкладке Available необходимо загрузить список доступных расширений, нажав на кнопочку "Load from". После чего нажать на "Install". Ознакомиться с расширением и требованиями к нему, можно на странице разработчика - щёлкнув по названию расширения.
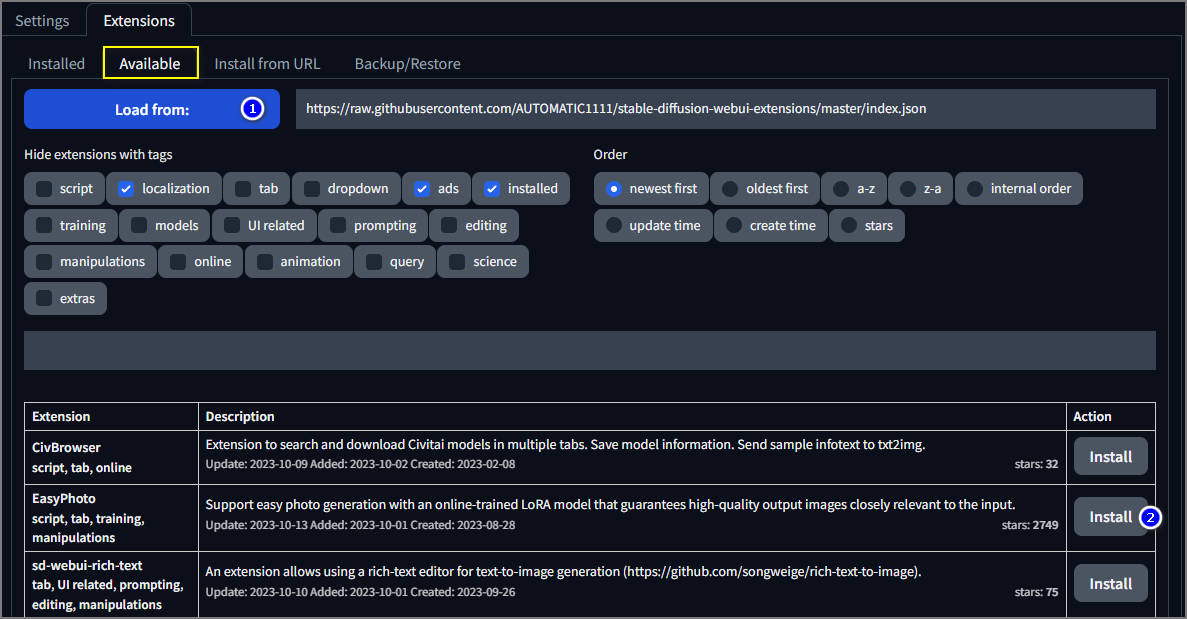
URL для установки берётся на странице разработчика. После нажатия на "install" внимательно смотрите что пишет в терминале, возможно расширение качает какую-то модель, а в самом автоматике ничего не происходит и непонятно что делается.
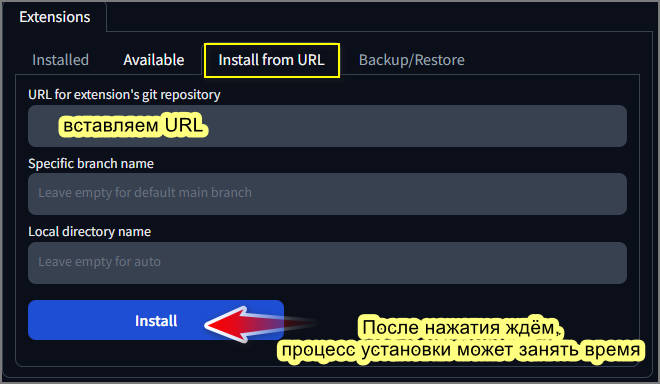
Батник - обычный текстовой файл с расширением .bat вместо .txt, отличается тем что после двойного щелчка на нём он не открывается, а исполняется его содержимое. То же самое можно получить запустив команду из командной строки находясь в папке с расширением. Вот пример команды копирования расширения adetailer с репозитория github.com:
git clone https://github.com/Bing-su/adetailer.git
В конце концов среди концов вы наконец должны нажать "Apply and restart UI". А ещё лучше закрыть окно терминала с автоматиком на крестик и запустить заново.
обновление AUTOMATIC1111

В самом низу страницы с Автоматиком, можно увидеть:
- Версию самого автоматика
- Версию Питона - языка программирования на котором всё строится и взаимодействует.
- Версию tourh - если простыми словами, то эта штука отвечает за скорость и точность генерации связывая методы глубокого обучения и cuda вашей видеокарты. Cuda - архитектура параллельного вычисления на множестве тензорных ядер. Тензорные ядра - специализированные блоки обработки данных внутри видеокарты.
- Xformers - библиотека для дополнительного ускорения генераций изображений.
- Gradio - версия графического интерфейса
- Checkpiont - буквенно-числовой код используемой модели для генерации, зависит от выбранной текущей модели для генерации изображения.
Если у Вас некая портабельная версия, то ищите файлик update.bat, запускаете от имени Администратора при закрытом Aвтоматике.
Если у Вас обычная установка, проверьте в корне основной папки Автоматика должен быть файлик webui-user.bat, открыв его блокнотом проверьте отсутствие символа @ перед командой git pull. Символ собачки комментирует строку, не позволяя ей выполняться, но при необходимости быстро вернуться к исполнению при удалении этого символа. Обновляться каждый раз смысла нет, ибо очередное обновление может сломать Автоматик до очередного обновления, поэтому рекомендуется делать его периодически, по мере надобности.
При появлении ошибок в ряде случаев помогает удаление, а лучше переименование, папки venv. После повторного запуска автоматика, эта папка должна перекачаться заново.
-

- git pull